Introduction to GraphQL for Developers
GraphQL is a powerful query language for APIs and a runtime for resolving queries with data. In this article, we’ll explore GraphQL’s core features, how to interact with a GraphQL API, and some development and operational challenges.

Kentaro Wakayama
24 November 2020

The Story of GraphQL
Nowadays, REST seems to be the default approach for building APIs, typically based on the familiar HTTP protocol. While REST is relatively simple to work with and enjoys widespread popularity, its use of multiple endpoints to address resources sometimes gets in the way of flexibility.
With such a rigid approach, some clients will get more data than they actually need (overfetching), whereas others will not get enough from a single endpoint (underfetching). This is a common issue among endpoint-based APIs like REST, and API clients have to compensate for it—for example, by issuing multiple requests and having to do the work of bringing data into the right shape on the client side.
With GraphQL, however, clients can request exactly the data that they need—no more and no less—similar to querying specific fields in a database. GraphQL was developed at Facebook in 2012, when the company was reworking its mobile apps and needed a data-fetching technology that was friendly even to low-resource devices. It was open-sourced in 2015 and moved to the GraphQL Foundation in 2018.
Features of GraphQL
GraphQL shares some similarities with REST. It allows clients to request and manage data from APIs via a request-response protocol, typically run on top of HTTP. However, the way that data is organized, requested, and served is very different.
GraphQL provides the following operations to work with data, via a single endpoint:
- Queries: Allow clients to request data (similar to a GET request in REST).
- Mutations : Allow clients to manipulate data (i.e., create, update, or delete, similar to POST, PUT, or DELETE, respectively).
- Subscriptions: Allow clients to subscribe to real-time updates.
Therefore, at the surface, GraphQL can cover your typical API requirements. Do not be misled by the “QL” into thinking that it’s used just for data retrieval.
A GraphQL API is based on a type system or schema which describes the capabilities and data structures of the API. The schema is defined using the GraphQL Schema Definition Language (SDL) and includes all the different types, their fields, and how they are related. Using a feature called introspection, clients can query the schema itself. This functionality is particularly useful for tooling, such as code generation and autogeneration of API documentation. For example, projects such as GraphiQL and GraphQL Playground leverage this functionality to provide rich documentation and integrated querying experiences.
What makes GraphQL so powerful is that clients can request exactly the data they need, not more and not less. It’s also possible to request related data in the same query without the need for additional API calls. We’ll see some examples in the next section.
A GraphQL server evaluates each incoming API request and resolves the values for each requested field using resolver functions. The resolver functions are doing the "real work" by, for example, fetching data from databases or other systems. This makes GraphQL an ideal solution for heterogeneous environments where data is located in different sources.
Working with GraphQL
In order to understand a little better what it’s like to interact with a GraphQL API, let’s take a look at a few simple examples. We’re going to use an updated Star Wars example server, which provides a fully functional GraphQL API with some example data, as well as GraphQL Playground. Simply follow these instructions to get it up and running:
- Clone the example repository:
$ git clone https://github.com/coder-society/starwars-server
- Install dependencies:
$ cd starwars-server
$ npm install
- Start the GraphQL server:
$ npm start
- Visit http://localhost:8080/graphql to access the GraphQL Playground interface.
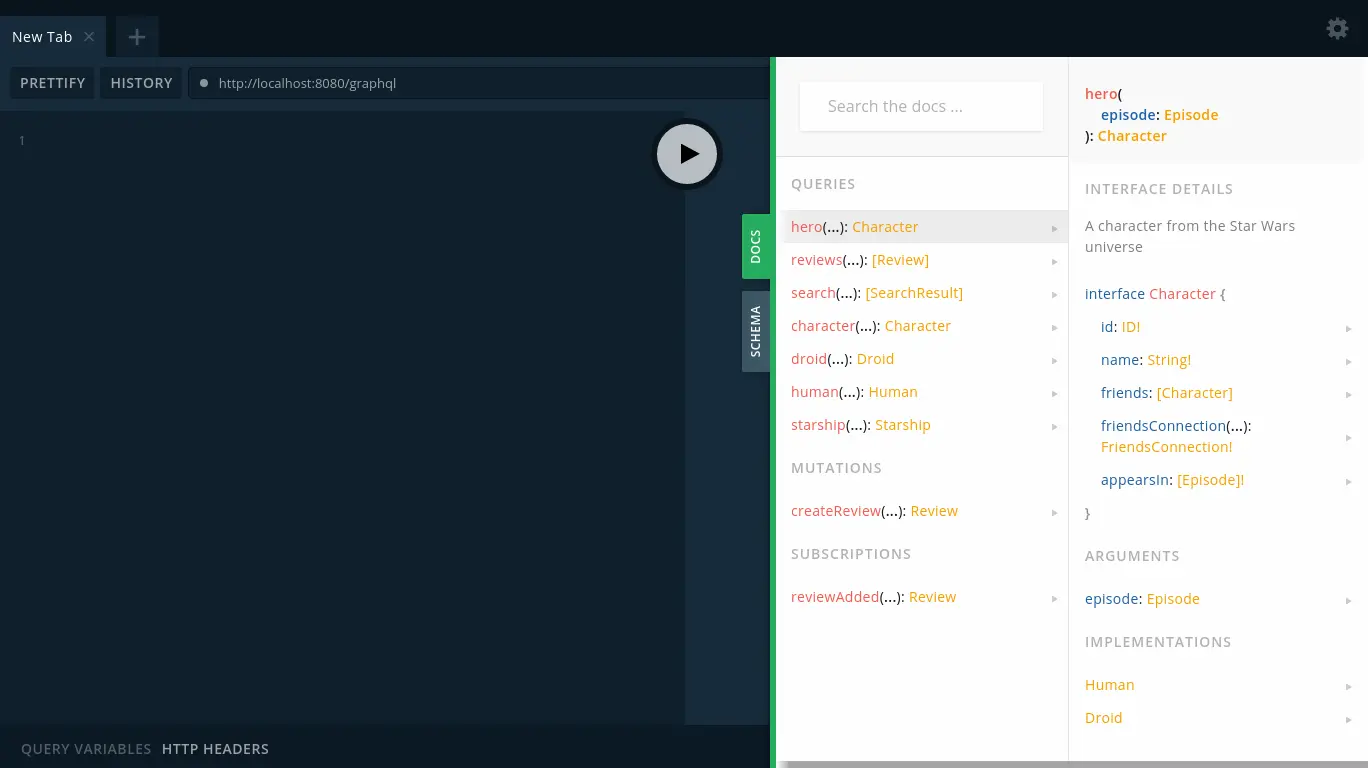
So here we are, looking at an unfamiliar API for the first time. Where do we start? What does it offer? Fortunately, GraphQL Playground provides rich API and schema documentation by leveraging GraphQL’s introspection feature. Simply click on the “Docs” or “Schema” tab on the right to explore the API.
Queries
You can use the information in the API docs to create your first query:
query {
humans {
id
name
}
}
This humans query gives us a list of entities, which are of type Human, and we list the fields we want returned inside the inner curly brackets. In this case we’re specifying that we want id and name, but we could also have returned any combination of fields supported by the Human type. This returns the following output:
{
"data": {
"humans": [
{
"id": "1000",
"name": "Luke Skywalker"
},
{
"id": "1001",
"name": "Darth Vader"
},
{
"id": "1002",
"name": "Han Solo"
},
{
"id": "1003",
"name": "Leia Organa"
},
{
"id": "1004",
"name": "Wilhuff Tarkin"
}
]
}
}
If we wanted to get specific information about one of these humans, we could use the human query, passing in the specific id value as an input to the query, as shown below:
query {
human (id: 1001) {
homePlanet
}
}
Again, the data we get back in the response corresponds to the fields we requested, as shown below:
{
"data": {
"human": {
"homePlanet": "Tatooine"
}
}
}
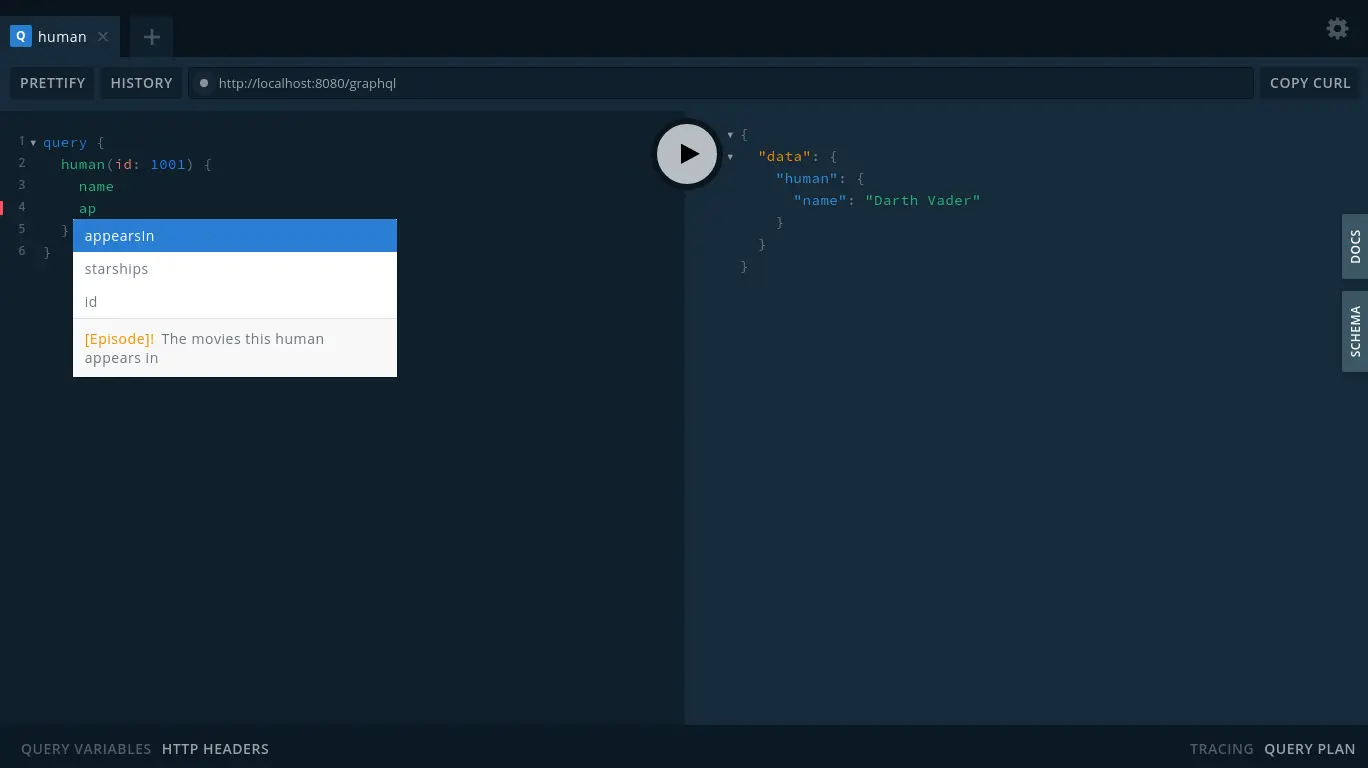
You can add other fields that you want returned, which you can discover by examining the aforementioned API and schema documentation, or simply by seeing the suggestions in GraphQL Playground as you type. Let’s try a slightly bigger query:
query {
human(id: 1001) {
homePlanet
name
appearsIn
starships {
id
name
}
}
}
This is a little more interesting because it also queries related data, in this case a starships field, in which we are arbitrarily retrieving the id and name of a list of starships (entities of type Starship). The response for this query is:
{
"data": {
"human": {
"homePlanet": "Tatooine",
"name": "Darth Vader",
"appearsIn": [
"NEWHOPE",
"EMPIRE",
"JEDI"
],
"starships": [
{
"id": "3002",
"name": "TIE Advanced x1"
}
]
}
}
}
While there is a lot more to be said about querying GraphQL APIs, these simple examples demonstrate how easy it is to consume a GraphQL API. With a single API, it’s possible to serve a wide variety of clients with very different needs. For example, a mobile client might want to request only a subset of the data that a web app would need.
Mutations and Subscriptions
GraphQL can do more than just query data. The Star Wars example we’re using provides one mutation example (adding a review) and one subscription example (getting notified when a review is added).
Let’s go back to GraphQL Playground and execute the following to start a subscription:
subscription {
reviewAdded {
episode
stars
commentary
}
}
What this does is to wait for updates related to a review being added, and when they’re available, it returns the episode, stars, and commentary fields. Just as with queries, we choose what data we’re interested in receiving.
Since we can’t continue writing queries while listening on a subscription, we can simply open a new tab in GraphQL Playground and execute the following mutation:
mutation {
createReview(episode: NEWHOPE, review: {
stars: 5,
commentary: "Awesome"
}) {
episode
stars
commentary
}
}
As with queries, the inputs are in the round brackets (including a non-trivial review object in this case), and the outputs are listed in curly brackets. In this particular example, the inputs and outputs are the same, which is not very useful; however, the output of a mutation can be used to retrieve information about a newly added entity, such as an identifier. The result of this mutation is the following:
{
"data": {
"createReview": {
"episode": "NEWHOPE",
"stars": 5,
"commentary": "Awesome"
}
}
}
Since we have an active subscription, you’ll see the above data reflected in that subscription, even as you continue adding reviews.
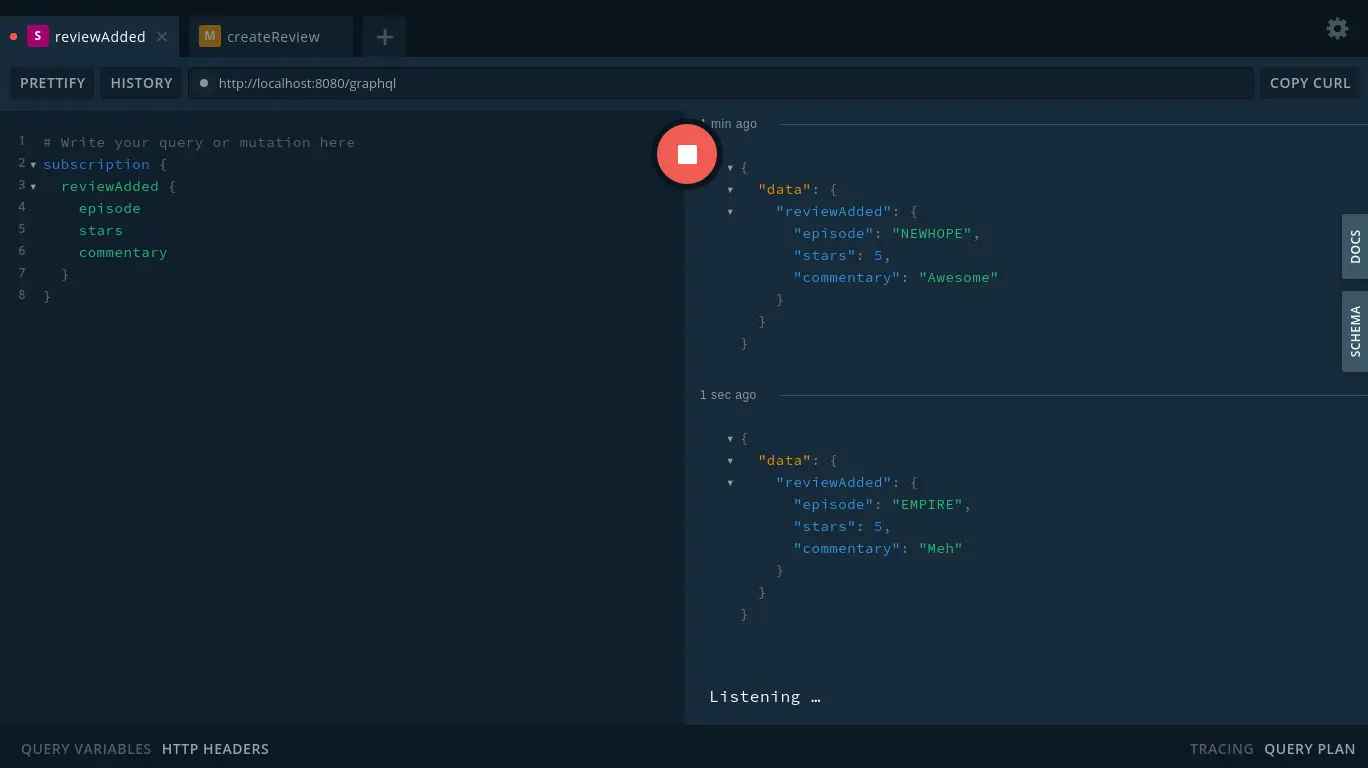
Whether you want clients to query data, manipulate it, or receive real-time updates, GraphQL has you covered. It also offers a lot more functionality that we haven’t covered, so please check the Queries and Mutations documentation to learn more about the available features.
GraphQL in the Real World
There is always a difference between developing software and running it in a production environment. In the case of GraphQL, it would be a shame to talk about its merits and fail to mention some of the challenges, tools, and techniques involved in using it successfully in real-world scenarios.
Effort
GraphQL’s flexibility comes at a cost. GraphQL has a bigger learning curve than REST, and it takes some getting used to. It also requires care to understand and define every field that can be requested, since GraphQL is by its nature declarative.
GraphQL involves a certain amount of complexity in developing and maintaining APIs. Tooling is evolving quickly, and it takes a fair amount of effort to keep up with all the new developments. Some tools, such as GraphQL Code Generator, can help speed up development, but it’s also important to be aware of any challenges and limitations (e.g., Apollo Federation currently does not support subscriptions).
Performance
Optimizing APIs and making sure they remain performant is a common theme among API technologies. However, with GraphQL it’s easy to run into what is called the N+1 problem. Let’s say that each article on a blog has a list of comments. Because of the way GraphQL executes resolvers, it will retrieve a list of articles (1 query), and for each article it will again retrieve a list of comments (n queries). This may lead to performance problems where too many operations are executed for a single query.
The GraphQL DataLoader provides a solution to this problem. Not only does it batch similar requests to minimize roundtrips, but it also offers a basic caching mechanism.
Security
GraphQL APIs, like other types of APIs, need to be hardened to ensure that only authorized clients can access the available data, and to prevent malicious or accidental denial of service. The former can be addressed using standard authentication/authorization techniques such as JSON Web Tokens, where restrictions can be applied across the whole API or on field level. The latter involves making sure that heavy queries do not cripple the API by limiting the depth, complexity, and server time allocated to queries.
If you are using internal types that should not be publicly accessible, it’s also important to secure introspection queries to make sure internals are not leaked.
Federation
Apollo Federation is a solution for how to work with GraphQL in a distributed system. API clients should only be concerned with one data graph and a single GraphQL API endpoint, no matter how many GraphQL servers your architecture is made of.
Other Considerations
There are many other things to consider when deploying a GraphQL API, including:
- Caching: GraphQL’s great flexibility means that queries are very unpredictable and thus difficult to cache. Also, it is common practice to send queries over HTTP POST requests, which by their very nature are difficult to cache. Some client libraries, such as Apollo Client, mitigate this by providing advanced client-side caching features.
- API versioning : GraphQL has a built-in deprecation mechanism, and it generally encourages APIs to evolve and retain backwards compatibility rather than introducing completely separate versions.
- Uploading files: File upload is not part of the GraphQL spec, so you’ll need to resort to workarounds or choose specific GraphQL servers which provide this functionality.
Wrapping Up
GraphQL is a fantastic technology for building evolvable and dynamic APIs that can adapt to the needs of diverse clients and use cases. It takes some getting used to, and it does have its development and operational challenges, like any other technology. Therefore, it’s important to understand that GraphQL is another tool in your toolkit, and not something that makes REST obsolete. If you want to learn more about GraphQL and how it can help you build a future-proof API, don’t hesitate to reach out to us.
For our latest insights and updates, follow us on LinkedIn